Download: source or winSVM.exe - last updated 15 July 2005
Download example files: train.txt validation.txt test.txt
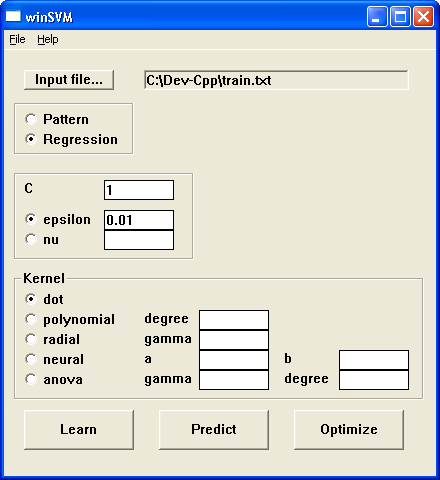
The software can perform both pattern recognition and regression, the following example uses regression. (A winSVM tutorial which uses classification written by Marc Block is available here.)
This is an exercise in supervised learning, we are given the following input/output data. Given future inputs, we wish to predict (unknown) outputs.
| input 1 | input 2 | output |
| 7 | 0 | 7 |
| 9 | 1 | 10 |
| 4 | 6 | 10 |
| 3 | 8 | 11 |
| 9 | 4 | 13 |
| 3 | 8 | 11 |
| 5 | 4 | 9 |
| 6 | 0 | 6 |
| 3 | 8 | 11 |
| 4 | 5 | 9 |
| 0 | 1 | 1 |
| 3 | 8 | 11 |
| 9 | 0 | 9 |
| 3 | 0 | 3 |
| 2 | 9 | 11 |
| 1 | 4 | 5 |
| 7 | 9 | 16 |
| 0 | 9 | 9 |
| 1 | 8 | 9 |
| 2 | 3 | 5 |
Split the data into three sets (in the ratio 50%, 25%, 25%).
Save the training set as train.txt in the following format:
@parameters
#training set
@examples
format xy
7 0 7
9 1 10
4 6 10
3 8 11
9 4 13
3 8 11
5 4 9
6 0 6
3 8 11
4 5 9
Click on "Input file..." and select 'train.txt'.
Enter '100' for the number of runs.
Click on "Optimize".
Inspect input-opt.csv, and note which parameters produce a low mean squared error (MSE).
With the given example, epsilon with a low value and a kernel of type dot appear to be optimal.
So for this particular data set, enter any value for C (say, 1), a low value for epsilon (say, 0.01) and select the dot kernel on the user interface.
Click 'Learn'.
Open 'train-svm.txt'
It contains the training set with alpha-values. Copy and paste this, plus the validation set into a new file and save it as 'validation.txt':
@parameters
# training set
@examples
dimension 2
number 10
b -0.00224081523342617
format xya
7 7.676151381197371e-017 7 -0.1797849206983427
9 1 10 0.06802209641651072
4 6 10 0
3 8 11 0
9 4 13 1
3 8 11 0.0916387839347123
5 4 9 0
6 7.676151381197371e-017 6 -1
3 8 11 0.02012404034711963
4 5 9 0
# validation set
@examples
format xy
0 1 1
3 8 11
9 0 9
3 0 3
2 9 11
Click on "Input file..." and select 'validation.txt'.
Click on "Predict".
Inspect 'validation-pred.txt'.
Continue to adjust kernel parameters, 'Predict', inspect 'validation-pred.txt' until the results are closest to the actual validation set outputs. In this instance, we stick with a dot kernel.
Copy the training-set-with-alphas and the test set into a new file called 'test.txt':
@parameters
# training set
@examples
dimension 2
number 10
b -0.00224081523342617
format xya
7 7.676151381197371e-017 7 -0.1797849206983427
9 1 10 0.06802209641651072
4 6 10 0
3 8 11 0
9 4 13 1
3 8 11 0.0916387839347123
5 4 9 0
6 7.676151381197371e-017 6 -1
3 8 11 0.02012404034711963
4 5 9 0
# test set
@examples
format xy
1 4 5
7 9 16
0 9 9
1 8 9
2 3 5
Click on "Input file..." and select 'test.txt'.
Click on "Predict".
Inspect the file 'test-pred.txt':
# examples ys
5.00009
15.9998
9.00001
9
5.00008
Remember the actual outputs:
5
16
9
9
5
Not bad, huh? That is because the above example was both linear and noise-free. However, it's with noisy nonlinear real-world data that the support vector machine shows its real strengths. Enjoy!
winSVM is based on mySVM, and unfortunately part of mySVM was working incorrectly (only the "predict" part worked) when I wrote winSVM, so in order to get it to work, you need to follow the instructions above even if they seem slightly protracted.
This software is free only for non-commercial use.
|
